Dica rápida...que tal desenvolver apps para android/iOS "like a PRO", usando .NET MAUI?!
Com estes dois incríveis tutoriais do @JamesMontemagno isto é totalmente possível.
Bom estudo!



![]()
quinta-feira, 20 de abril de 2023
quarta-feira, 23 de novembro de 2022
CRM-GT - Painel de Gráficos

- Área Polar
- Barra Empilhada
- Barra Horizontal
- Barra Vertical
- Círculo
- Círculo (metade)
- Contador
- Filtro
- Funil
- Gauge
- Linha
- Mapa
- Pizza
- Tabela
A área de [Configuração do Painel] é onde criamos os registros que representam os gráficos. Cada registro representa um gráfico.


Cadastramos um novo gráfico da seguinte maneira:
- Para o campo [Grupo] informamos um valor que vai representar um Label para uma [aba] que será criada para o gráfico. Então, se colocarmos, por exemplo "Vendas", teremos

- O campo [nome] será o [título] do gráfico
- Escolha o tipo de gráfico no lookup de tipos (12 possíveis)
- Informe uma largura (em px)
- Informe uma altura (em px)
- O campo [ordem] (read only aqui) mostra em qual posição ficará o gráfico em relação a outros do [mesmo grupo]. Você pode reordenar os gráficos clicando no botão [Reordenações]


- No campo [Query Exec] é onde informamos a Fonte de Dados para o gráfico. Clique no link [Abrir Query Exec] para Criar/Editar sua query. Para a maioria dos gráficos você precisa informar os valores para o eixo X e Y do gráfico. No exemplo baixo, para um gráfico de barras, mostraremos um total (SUM de totalamount) agrupados pelo [nome do Pipeline]

- Note que na query existem algumas macros iniciadas com a palavra [@ChartFilter_]. Este é um recurso para que possamos filtrar os dados por qualquer campo que desejarmos, obtidos a partir da tela, na área de [Filtro]. Para adicionar filtros no gráfico, criamos um [novo] registro de gráfico, escolhemos o tipo [Filtro] e informamos no campo [Grupo] o "mesmo valor" cadastrado para os outros registros de gráficos na qual desejamos aplicar os filtros. Pegando o mesmo exemplo já citado, para o gráfico de barras, que vai estar na ABA (ou Grupo) chamado "Vendas" vamos adicionar os seguintes filtros
- Data de / Até
- Contas



Note a relação então de registros para o [mesmo grupo].
No exemplo abaixo teremos [1] filtro que será usado para os gráficos pertencentes ao GRUPO "Vendas"

E para finalizar a configuração dos filtros, as [macros] devem estar presentes em [todas] as Query Execs para os registros exemplificados acima.
No momento da criação/alteração da Query Exec existe uma documentação completa no uso de todas as [macros], na aba [Dicas de Uso]

Então, lá vamos encontrar todas as formas possíveis de uso das macros [@ChartFilter_]
Gráfico - Tipo Tabela
Será visulizado um GRID com as colunas que você especificar no SELECT criado na Query Exec associada.
Você pode configurar a tabela para aceitar um [duplo clique] na linha para abrir o detalhe do registro correspondente na lista.
Então para que isto aconteça basta abrir a Query Exec associada e adicionar o ID (com o label hidden_id) da tabela em questão e o [Nome da Tabela] também (com o label hidden_table).
Exemplo, vamos mostrar num Grid os registros da tabela de Oportunidade. Portanto, ficará da seguinte forma

No gráfico do tipo Contador, será mostrado um balão, e centralizado nele o valor que você [agregou] na Query Exec associada.
Na Query Exec você deverá especificar 3 campos
- Agragador com o alias [count]
- Um descritivo qualquer chamado [label]
- Um valor RGB com o alias [rgbcolor]


Para o gráfico do tipo mapa, informe na Query Exec associada os campos
- Um descritivo qualquer com o alias [title]
- O mesmo descritivo acima com o alias [infoTitle]
- Um descritivo detalhado com o alias [infoDetail]
- Uma latitude com o alias [latitude]
- Uma longitude com o alias [longitude]


Este importante recurso permite ver mais detalhes de uma parte específica do seu gráfico. Exemplo, em um gráfico de barras, se você clicar em uma barra específica, o sistema abre um popup com os registros referentes aquela barra.
Este recurso já está habilitado por padrão nos gráficos de
- Área Polar
- Barra Empilhada
- Barra Horizontal
- Barra Vertical
- Funil
- Linha
- Pizza
Por padrão, o popup somente mostra o campo [name] na lista de registros. Mas você pode configurar a Query Exec para ter os campos adicionais que desejar.
Para isto adicione, entre aspas, os campos desejados (separe os campos usando o caracter pipe [|] ), e nomeie este valor com o alias [drilldownfields]

Neste exemplo eu adicionei o campo [name] da opportunity e o [name] da tabela Status. Lembre-se de adicionar um LEFT JOIN se as tabelas relacionadas (Status no caso) não estiverem na Query.
Clicando na barra [Em Desenvolvimento]

E o detalhe

segunda-feira, 10 de maio de 2021
[CRM-GT] - Javascript Functions (SDK)

Vamos a elas!
CRMGT.UserConfig
Profile(userEmail = "")
Namespace: CRMGT.UserConfig
Obtenha várias informações sobre o usuário logado no sistema, como:
- userId - Guid do usuário
- userName - Nome do usuário
- userEmail – E-mail do usuário
- orgName – Nome da Organização do usuário
- userProfile – Json contendo uma lista com todas as informações do perfil do usuário (ids, nomes dos departamentos/funções nos departamentos)
Segue um exemplo de retorno das propriedades citadas acima no Console do browser:

CRMGT.Env
Delay(ms)
Namespace: CRMGT.Env
- Suspende a execução de um código até que o tempo limite seja alcançado (parâmetro passado, em milisegundos)
IsMobileDevice()
Namespace: CRMGT.Env
- Retorna true/false
IsEdge()
Namespace: CRMGT.Env
- Retorna true/false
IsFireFox()
Namespace: CRMGT.Env
- Retorna true/false
IsSafari()
Namespace: CRMGT.Env
- Retorna true/false
IsOpera()
Namespace: CRMGT.Env
- Retorna true/false
OrganizationName()
Namespace: CRMGT.Env
- Retorna o nome da organização corrente
Language()
Namespace: CRMGT.Env
- Retorna o idioma corrente do site (ptBr, enUs, etc)
ResizeFrame(resize [true|false])
Namespace: CRMGT.Env
- Ativa / Desativa o resize automático de uma página do site
CanResizeFrame()
Namespace: CRMGT.Env
- True/false – Consulta se pode efetuar o resize de uma página do site
FormatDateStringToISO(strDate)
Namespace: CRMGT.Env
- Retorna uma data passada por parâmetro no formato ISO (International Organization for Standardization), levando em consideração o idioma corrente (CRMGT.Env.Language()):
- Exemplo de retorno: 2019-06-21T15:32:00
-
Exemplo para atualização de um campo no form do tipo [DATETIME]
CRMGT.Page.Util.SetAttributeValue("resolutionDateTime", CRMGT.Env.FormatDateStringToISO(new Date()));
-
Para atualização de um campo do tipo [DATE] somente, passe diretamente a data desejada no formato YYYY-MM-DD
Exemplo:
var currDate = new Date(); var currDateOnly = `${currDate.getFullYear()}-${(currDate.getMonth() + 1).padLeft(2)}-${(currDate.getDate()).padLeft(2)}`; CRMGT.Page.Util.SetAttributeValue("dateOnlyTest", currDateOnly);
CRMGT.Page.Util
Utilize as diversas funções abaixo para busca e manipulação de dados nos formulários do sistema.
Note que em muitas das funções existe um parâmetro booleano chamado [fromParentRecord].
Ele é útil quando precisamos buscar algum dado da tela [anterior].
Por exemplo, ao editar um registro de contato, no final da tela existe a seção [Anotações e Visão 360]. Nesta seção temos abas (com subGrids) que mostram diversas atividades relacionadas ao contato. Você pode, neste ponto, criar um novo registro de atividade relacionado. Neste momento um popup se abre para o cadastro. É neste ponto que podemos buscar algum dado da tela [pai] (no nosso ex, de contato) para preencher na tela de popup usando então o parâmetro [fromParentRecord como true].
DownloadZippedFilesInTableAttachment(zipFileName, tableName, recordIds)
Namespace: CRMGT.Page.Util
Utilize este método para retornar um ZIP (em forma de download) de todos os anexos relacionados a uma tabela do sistema, para um ou vários registros.
Passe como parâmetro o nome desejado do arquivo ZIP, o nome da tabela para busca dos anexos (schemaName da tabela) e o ID do registro (mais de um registro, separe-os por vírgula).
EncodingUTF8Base64(str)
Namespace: CRMGT.Page.Util
Utilize este método se precisar passar alguma string complexa, com caractéres especiais, acentos, conteúdo html, símbolos, etc, diretamente para ser atualizada no banco de dados do CRM.
Isto pode acontecer, por exemplo, se usarmos o método QueryExecData, passando como parâmetro esta string complexa para alguma QueryExec efetuar um update.
Como esta string vai estar no formato Base64, o local que vai receber este valor precisa convertê-la.
Pensando no exemplo de uma QueryExec, podemos, via comando de banco de dados, converter da seguinte forma:
Exemplo em MySQL:
SET @convertedValue = SELECT CAST(FROM_BASE64(@SuaVarNaBase64) AS CHAR);
Se estiver usando o banco de dados SQL SERVER no produto, esta função (EncodingUTF8Base64) não é necessária. Utilize o comando javascript [window.btoa()] para converter para a base64, e no Sql Server converta da seguinte forma:
DECLARE @convertedValue VARCHAR(MAX) = (SELECT CONVERT( VARCHAR(MAX), CAST(N'' AS XML).value('xs:base64Binary(sql:column("base64Value"))', 'varbinary(max)') ) FROM (SELECT @SuaVarNaBase64 base64Value) t);
DoNotTraceElementOnSave(id)
Namespace: CRMGT.Page.Util
Todos os campos alterados do formulário são rastreados e salvos quando o usuário clica no botão Salvar.
Se precisar pedir para o sistema ignorar, não rastrear um determinado campo ao salvar, adicione este método no Onload do form, passando o id do campo como parâmetro.
CopyFieldsFromParentForm(exceptions)
Namespace: CRMGT.Page.Util
Utilize esta função quando precisar copiar todos os campos da tela [pai] quando estiver criando um registro de [subGrid].
A função vai buscar todos os campos [iguais] da tela relacionada na tela pai.
Exemplo, você está editando um registro de [incident].
No final do formulário existe a seção [Anotações e Visão 360].
Uma das abas desta seção é o relacionamento da incident com ela mesma; o nome da aba está geralmente como [Chamados].
Quando você clicar para criar um novo chamado relacionado (botão [criar] do subGrid), neste ponto você pode precisar copiar todos os campos do chamado principal neste chamado relacionado.
A função [CopyFieldsFromParentForm] vai então fazer este mapeamento/cópia.
Se precisar pedir para a função [ignorar algum campo, ou vários], passe o nome dos campos no parâmetro [exceptions], separados por vírgula.
AutoSaveRecordAddingSubGridItem(value, refreshForm = false)
Namespace: CRMGT.Page.Util
Por padrão, ao adicionar um item em um dos sub-Grids no formulário, aparece a mensagem para o usuário salvar o registro principal do form para de fato salvar todos os itens inseridos.
Com esta opção de SDK podemos alterar este comportamento.
Passando o param [value] como true, dizemos para o sistema salvar automaticamente o registro principal a [cada] item inserido no sub-Grid.
Também é opcional se deseja dar um [refresh] no form (param refreshForm).
 Note que, se o usuário estiver [criando um novo] registro principal, ao adicionar o [primeiro item] de um sub-Grid, o sistema faz o refresh automaticamente.
Note que, se o usuário estiver [criando um novo] registro principal, ao adicionar o [primeiro item] de um sub-Grid, o sistema faz o refresh automaticamente.
CryptographyValue(value)
Namespace: CRMGT.Page.Util
O valor passado como parâmetro é retornado como um valor criptografado (modelo de criptografia AES).
GetToken(organization, clientId, clientSecret, renewIfExpired)
Namespace: CRMGT.Page.Util
Retorna um Token para acesso ao Conector de Dados** do CRM-GT.
** veja em Funcionalidades -> Conector de Dados
Segue um exemplo de execução e o retorno do token:

Passe as credentiais (clientId e ClientSecret) convertidas na [base64 string], através da função BTOA conforme destacado na imagem acima.
Estas credenciais são criadas pelo [administrador] do sistema e repassada para os desenvolvedores/clientes.
O retorno é um JSON contendo o token, ou o detalhe do erro na tentativa de obtenção do token.
RenewToken(organization, clientId, clientSecret)
Namespace: CRMGT.Page.Util
Retorna um Token [renovado] para acesso ao conector do CRM-GT.
Utilize o exemplo da função [GetToken] acima para a execução do [RenewToken].
CheckAccessToken(data, organization, clientId, clientSecret)
Namespace: CRMGT.Page.Util
Para tratarmos falhas na execução da webAPI, por falha de Token, podemos usar a func [CheckAccessToken]
Então, dentro do callback [success] do ajax, você pode adicionar o seguinte código:
}, success: function (data, textStatus, jqXHR) { let checkConnection = CRMGT.Page.Util.CheckAccessToken(data, organization, clientId, clientSecret); if (checkConnection.IsInvalid) { token = checkConnection.RenewedToken; ReExecutaSuaFuncaoAqui(); }
Atualize sua variável de token com a nova e execute novamente sua função conforme indicado (ReExecutaSuaFuncaoAqui()).
GetParam(name, windowTop)
Namespace: CRMGT.Page.Util
Retorna o [valor] de um parâmetro da [Query String] da página corrente - ou da janela superior do navegador (window.top).
GetPageContentFromCurrentDialog()
Namespace: CRMGT.Page.Util
Retorna o contentDocument (DOM) de uma página HTML aberta pelo método ShowDialog (que é explicado em detalhes nesta documentação).
RefreshForm()
Namespace: CRMGT.Page.Util
Execute este método para dar um Refresh na página.
RefreshList()
Namespace: CRMGT.Page.Util
Execute este método para dar um Refresh em uma Lista de Registros.
Save(redirectToList = false)
Namespace: CRMGT.Page.Util
Execute este método para salvar o registro corrente.
Se precisar redirecionar a tela para a lista de registros após o Save, passe [true] para o parâmetro [redirectToList].
SaveAndNew()
Namespace: CRMGT.Page.Util
Execute este método para salvar o registro corrente e preparar a página para um novo cadastro.
SaveGridEdit(saveParent = false)
Namespace: CRMGT.Page.Util
Execute este método para salvar o registro de um [sub-Grid] relacionado em um registro principal.
Exemplo, podemos pedir para o sistema salvar uma [Linha de Contrato], fechar o popup e salvar o Form Pai (de Contrato)
CRMGT.Page.Util.SaveGridEdit(true);
ParseValueToDecimalString(value, numOfDecs, valueFormattedAs = "pt-BR", removeCommas = false)
Namespace: CRMGT.Page.Util
Execute este método para converter corretamente uma string para um valor decimal.
Por padrão, [pt-BR] é o formato usado. Para usar outro formato passe o desejado no parâmetro [valueFormattedAs].
Exemplo:
var pricelist = CRMGT.Page.Util.GetAttribute("pricelist"); var pricelistValue = CRMGT.Page.Util.ParseValueToDecimalString(pricelist.val(), 2);
FormatDecimalField(field, format = "#.##0,00", useReverse = true)
Namespace: CRMGT.Page.Util
Execute este método para adicionar uma [máscara] formatada no seu campo de valor
Por padrão, [#.##0,00] é a máscara usada. Para usar outra máscara passe o desejado no parâmetro [format].
Exemplo:
CRMGT.Page.Util.FormatDecimalField("totalamount");
GridViewButtonsOnClick(subGridId, btnType, funcName)
Namespace: CRMGT.Page.Util
Método que auxilia na inserção de função Javascript customizada, que será executada ao clicar nos botões [Criar], [Editar] ou [Excluir] da toolbar de uma [Sub-Grid].
Adicione este método no [OnLoad] do formulário.
Temos os seguintes parâmetros:
-
subGridId - representa o [id] do campo criado como tipo [Relacionamento N-N]
Por exemplo, na tabela de Oportunidade temos, na lista de campos criados, um do tipo [ComplexRelationship] chamado [opportunityproduct], que é um SubGrid de [Produtos da Oportunidade]. Portanto subGridId será "opportunityproduct". - btnType - Representa o tipo de botão onde adicionaremos a chamada do JS customizado, onde podemos passar o valor [add], [edit] ou [delete]
- funcName - O nome da função desejada para ser executada ao clicar no botão
Exemplo, ao clicar no botão [Criar] de um sub-grid de produtos da oportunidade, precisamos executar um método JS chamado "CanCreateNewItem" (que deve estar localizado no [OnLoad] do form).
CRMGT.Page.Util.GridViewButtonsOnClick("opportunityproduct", "add", "CanCreateNewItem()");
 Se desejarmos [interromper] a ação do [clique] do botão, podemos usar CRMGT.Page.Util.GridViewButtonResult(false); dentro do método customizado (no exemplo, dentro de "CanCreateNewItem")
Se precisarmos fazer uma pergunta de decisão, onde somente após o clique no botão [sim] é que poderemos abrir a tela popup do botão do sub-grid [criar], adicionamos no código:
Se desejarmos [interromper] a ação do [clique] do botão, podemos usar CRMGT.Page.Util.GridViewButtonResult(false); dentro do método customizado (no exemplo, dentro de "CanCreateNewItem")
Se precisarmos fazer uma pergunta de decisão, onde somente após o clique no botão [sim] é que poderemos abrir a tela popup do botão do sub-grid [criar], adicionamos no código:- CRMGT.Page.Util.GridViewButtonConfirmDialogMessage("Sua Mensagem de Confirmação");
-
CRMGT.Page.Util.GridViewButtonAdditionalFuncToRun("customFunc()");
Quando o usuário clicar no botão de confirmação [sim] você pode executar uma função sua customizada antes de abrir o popup.
Importante: No nosso exemplo, os métodos [GridViewButtonConfirmDialogMessage] e [GridViewButtonAdditionalFuncToRun] deverão ser adicionados dentro da função CanCreateNewItem
Se precisarmos atualizar o conteúdo de um subGrid (refresh), adicionamos no código:- CRMGT.Page.Util.ReloadGridView(relationshipTableId, fieldId, parentId, parentIdName); Onde:
- relationshipTableId - representa o Metadata ID da tabela associada ao subGrid (obtemos este id acessando a tabela interna do sistema chamada Entity)
- fieldId - representa o ID do subGrid (este id é obtido em Configurações -> Tabelas do Sistema, aba Campos, do tipo [complexrelationship])
- parentId - representa o ID da tabela pai onde o subGrid está associado (por exemplo, temos um subGrid de Produtos da Oportunidade associado a tabela pai [Oportunidade]). Geralmente podemos obter este id executando CRMGT.Page.Util.GetEntityRecordId()
- parentIdName - representa o nome do campo chave da tabela pai onde o subGrid está associado (no exemplo citado acima para o parâmetro parentId, teremos como parentIdName [opportunityid])
ToBoolean(value)
Namespace: CRMGT.Page.Util
- Método para converter uma string em Boolean.
REST_GetString(url)
Namespace: CRMGT.Page.Util
- Executa uma REST API e retorna o resultado da mesma.
DateDiff(datePart, startDate, endDate)
Namespace: CRMGT.Page.Util
- Método para retornar a diferença entre duas datas.
-
No parâmetro [datePart] podemos passar como desejamos a diferença, sendo possível em:
Day
Month
Year
Hour
Minute
Second
IsNullOrEmpty(value)
Namespace: CRMGT.Page.Util
- Método para verificar se o valor passado como parâmetro está vazio ou nulo.
HasDuplicateDetection(entityName, jsonFields)
Namespace: CRMGT.Page.Util
- Use esta função para bloquear um cadastro em duplicidade no sistema.
- Informe a tabela desejada em os campos para busca no banco de dados.
-
Segue um exemplo de uso, no [OnSave] do formulário:
if (CRMGT.Page.Util.GetCanSaveRecord()) { var _name = $("#name").val(); var _accountnumber = $("#accountnumber").val(); var jsonFields = []; jsonFields.push({ "fieldname":"name", "fieldtype": "varchar", "fieldvalue": _name }); jsonFields.push({ "fieldname":"accountnumber", "fieldtype": "varchar", "fieldvalue": _accountnumber }); CRMGT.Page.Util.SetCanSaveRecord(true); if (CRMGT.Page.Util.HasDuplicateDetection("account", JSON.stringify(jsonFields))) { CRMGT.Page.Util.SetCanSaveRecord(false); var msg = "Detecção de Duplicidade<br/><br/>"; msg += "Já existe uma Conta cadastrada com os valores:<br/>"; msg += "Nome: " + _name + "<br/>"; msg += "Número da Conta: " + _accountnumber + "<br/>"; ShowAlert(msg, 500, false, "font-size:18px;"); } }
- Neste exemplo, se existir um registro com o mesmo valor dos campos [name e accountNumber] o registro não é salvo (através do uso do método [SetCanSaveRecord] com o parâmetro "false").
RunAssociatedWorkflowsSynchronously(value [true|false])
Namespace: CRMGT.Page.Util
- Método para ser usado no [OnLoad] do formulário.
- Passando o parâmetro [true], ao salvar um [novo] registro, ou alterar um registro [existente], todos os Workflows associados ao registro serão executados imediatamente.
- Lembrando que serão executados os workflows correspondentes ao [modo] em que o registro está sendo salvo.
- Por exemplo, ao entrar em um registro existente, ao salvar, somente serão executados os workflows com a configuração de disparo (trigger) no modo [Atualização].
Se existirem subGrids associados no formulário, o sistema também vai executar os workflows (trigger de criação) relacionados as tabelas destes subGrids. Por exemplo, no formulário de Oportunidade vai existir um subGrid de Produtos da Oportunidade. Portanto os workflows associados na tabela [produto da oportunidade] serão também executados de forma síncrona.
GetAttachmentContentById(attachmentNoteId)
Namespace: CRMGT.Page.Util
- Retorna o conteúdo de um anexo, como uma string na base64.
- Passe como parâmetro o ID da AttachmentNote, que é a tabela que guarda os anexos.
HasFormAttachment()
Namespace: CRMGT.Page.Util
- Retorna true|false se existe pelo menos 1 anexo no formulário.
HasTimeLineAttachment()
Namespace: CRMGT.Page.Util
- Retorna true|false se existe pelo menos 1 anexo no componente [Time Line Annotation] do formulário.
BreakLineAfterAttribute(id, fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
-
Adiciona uma quebra de linha, no formulário, [após] o campo especificado por parâmetro
Exemplo: Após o campo [endereço] reposicionar os próximos na próxima linha da tela:

SetAttributeEntireLine(id, entireLinePos [true|false], fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
-
Mantém o campo (passado por parâmetro) como único na linha de campos do formulário
Exemplo:
HideSection(id, hide [true|false])
Namespace: CRMGT.Page.Util
-
Permite esconder/mostrar uma aba do formulário.
Passe como [id] a descrição da aba que deseja interagir.
HideAttribute(id, hide [true|false], fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Permite esconder/mostrar um campo do formulário
- Para esconder um campo na área de [Business Process Flow] habilitada na tela, utilize HideBPFAttribute(id, hide)
- Para esconder um campo do tipo [richText] passe o id concatenado desta forma: "richTextArea_" + id
SetRequiredAttribute(id, required [true|false], fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Altera o atributo [required] de um campo no formulário
DisableAttribute(id, disable [true|false], fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Desabilita um campo no formulário
- Para desabilitar um campo na área de [Business Process Flow] habilitada na tela, utilize DisableBPFAttribute(id, disable)
SetAttributeLabel(id, label, fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Altera o Label de um campo no formulário
SetLookupValue(lookupId, lookupValue, lookupLabel)
Namespace: CRMGT.Page.Util
- Preenche um lookup, com seu Guid/Texto
- Para preencher um lookup na área de [Business Process Flow] habilitada na tela, utilize SetBPFLookupValue(lookupId, lookupValue, lookupLabel)
-
Exemplo:
CRMGT.Page.Util.SetLookupValue("accountid", "4f0e7903-5e54-4a11-b596-816a4546fe54", "Conta LTDA");
SetMultiLookupValue(lookupId, lookupValue, lookupLabel)
Namespace: CRMGT.Page.Util
- Preenche um [Multi]Lookup, com seu Guid/Texto
- Parâmetro lookupValue - passe no seguinte formato:
- [Name da Tabela do Lookup] + [|] + [Guid da Tabela do Lookup] + [|] + [Guid da Entidade do Lookup] + [,] + [...]
- Exemplo: Conta Teste|13a3ef4f-d0de-40fb-a7a5-7568ae7ba542|585E0EEA-362F-423D-AEB3-131E8A956FC3
- O Guid [585E0EEA-362F-423D-AEB3-131E8A956FC3] representa o id da tabela [account] no Metadado do sistema
- Separe esta combinação de valores usando a [,] para preencher o campo com múltiplos valores
- Parâmetro lookupLabel - passe o nome que deverá aparecer no campo de texto do lookup. Para vários, separe-os por [,]
SetLookupOnChange(lookupId, fnOnChange)
Namespace: CRMGT.Page.Util
- Atribui um método para ser executado no OnChange do lookup
-
Exemplo:
CRMGT.Page.Util.SetLookupOnChange("accountid", "onChangeAccount([[id]], [[value]])");
Note que no método [onChangeAccount] foram preparados dois parâmetros, [[id]] e [[value]], com colchetes duplos.
Isto significa que o sistema vai passar o ID e o VALOR do Lookup que foi selecionado para seu método.
O uso deste mecanismo é [opcional].
- Para atribuir uma método em um lookup na área de [Business Process Flow] habilitada na tela, utilize SetBPFLookupOnChange(lookupId, fnOnChange)
SetTreeViewOnChange(treeviewId, fnOnChange)
Namespace: CRMGT.Page.Util
- Atribui um método para ser executado no OnChange do lookup do tipo TreeView
OnChange para campos diferentes de [Lookup]
-
Utilize JQuery para ativar o [change] de campos que são diferentes de lookup.
Exemplo de ativação para o campo [name]:
$("#name").unbind("change").change(function () { // ADICIONE SEU CÓD AQUI... });
ClearTreeViewLookup(treeviewId)
Namespace: CRMGT.Page.Util
- Limpa o conteúdo do lookup do tipo TreeView
GetLookup(lookupId, fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Retorna todos os dados de um lookup, sendo:
- Id, que é o lookupId passado por parâmetro
- Label, que é o nome que aparece no campo do lookup
- Value, que é o GUID do lookup
-
Exemplo:
var accountId = CRMGT.Page.Util.GetLookup("accountid").Value;
- Para retornar os dados de um lookup na área de [Business Process Flow] habilitada na tela, utilize GetBPFLookup(lookupId)
FilterLookupValue(lookupId, value)
Namespace: CRMGT.Page.Util
- Permite filtrar o conteúdo do lookup, para restringir os dados que serão mostrados para o usuário
- Para filtrar o conteúdo do lookup na área de [Business Process Flow] habilitada na tela, utilize FilterBPFLookupValue(lookupId, value)
-
Exemplo 1:
Filtra o lookup para mostrar somente as [Unidades] de uma determinada [Instituição]:
O filter [type] usado abaixo exemplifica uma busca em uma tabela do tipo [N-N]. Desta forma, devemos informar [nnrelationship], depois o símbolo de pipe [|] e por fim o [schema do campo].
var instituicaoId = CRMGT.Page.Util.GetLookupObject("instituicao_a52bd16faf87_id").ObjectValue.val(); var aFilter = []; var filter = new Object(); filter.field = "instituicoesid"; filter.type = "nnrelationship|unidade_instituicoes"; filter.value = instituicaoId; aFilter.push(filter); CRMGT.Page.Util.FilterLookupValue("unidade_874773c8a682_id", aFilter);
-
Exemplo 2:
Filtra um lookup de [Atividades do Projeto] baseado no lookup de [Projetos]
O código abaixo deve ser adicionado no [OnLoad] do formulário
Os campos de lookup usados no exemplo abaixo (por exemplo [timesheetproject_87b12b2ec835_id]) são criados internamente desta maneira pelo sistema.if (CRMGT.Page.Util.FormMode() == "edit") { OnChangeProject(); } CRMGT.Page.Util.SetLookupOnChange("timesheetproject_87b12b2ec835_id", "OnChangeProject()"); function OnChangeProject() { var projectId = CRMGT.Page.Util.GetLookup("timesheetproject_87b12b2ec835_id").Value; if (CRMGT.Page.Util.IsNullOrEmpty(projectId)) { CRMGT.Page.Util.FilterLookupValue("timesheetprojectactivity_de15ff33049c_id", null); return; } var aFilter = []; var filter = new Object(); filter.field = "timesheetprojectid"; filter.type = "uniqueidentifier"; filter.value = projectId; filter.conditiontype = (AND, OR, sendo AND o padrao); filter.operatortype = (=, !=, etc..., sendo = o padrao); aFilter.push(filter); CRMGT.Page.Util.FilterLookupValue("timesheetprojectactivity_de15ff33049c_id", aFilter); }
OBS: Note que o método [OnChangeProject()] é configurado na function [SetLookupOnChange] e executado também. Isto é importante quando estivermos editando um registro, para que os lookups fiquem corretamente relacionados.
-
Para o filter.type você pode usar os seguintes valores:
bit char nchar varchar nvarchar datetime int decimal text uniqueidentifier 1nrelationship|Nome da tabela relacional 1-N nnrelationship|Nome da tabela relacional N-N
GetLookupObject(lookupId, fromParentRecord)
Namespace: CRMGT.Page.Util
- Semelhante ao GetLookup, porém, retorna com mais informações para o desenvolvedor, sendo:
- EntityMetadataId, que é o GUID da [tabela do lookup] no metadado interno do sistema chamado [Entity]
- ObjectDiv, que representa o elemento DOM na tela
- ObjectLabel, que é o nome que aparece no campo do lookup
- ObjectValue, que é o GUID do lookup
-
Exemplo:
var accountId = CRMGT.Page.Util.GetLookupObject("accountid").ObjectValue.val();
IgnoreOnlyActiveRecordsInLookup(lookupId, ignore)
Namespace: CRMGT.Page.Util
-
Por padrão campos lookup sempre mostram os registros [ativos] na lista ou em uma pesquisa no campo.
Com este método podemos ignorar este comportamento, resultando em uma lista de resultado independente do status do registro.
Exemplo:CRMGT.Page.Util.IgnoreOnlyActiveRecordsInLookup("unidade_874773c8a682_id", true)
GetAttribute(id, fromParentRecord = false, frameId = "")
Namespace: CRMGT.Page.Util
- Retorna, como objeto jQuery, um elemento do DOM especificado.
-
Exemplo:
var _name = CRMGT.Page.Util.GetAttribute("name").val();
- Para retornar um elemento na área de [Business Process Flow] habilitada na tela, utilize GetBPFAttribute(id)
GetAttributeLabel(id, fromParentRecord)
Namespace: CRMGT.Page.Util
- Retorna o texto (ou label) associado a um campo do form
SetAttributeValue(id, value, fromParentRecord = false, frameId = "")
Namespace: CRMGT.Page.Util
- Atualiza o valor de um elemento do DOM especificado.
- Para atualizar o valor de um elemento na área de [Business Process Flow] habilitada na tela, utilize SetBPFAttributeValue(id, value)
SetRichTextAttributeValue(id, value, fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Atualiza o valor de um elemento [RichText] especificado.
GetRichTextAttributeValue(id, fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Obtém o valor de um elemento [RichText] especificado.
IsRichTextAttributeValueEmpty(id, fromParentRecord [true|false])
Namespace: CRMGT.Page.Util
- Retorna true/false - Verifica se o conteúdo de um elemento [RichText] está vazio.
DisableRichTextAttribute(id, disable [true|false])
Namespace: CRMGT.Page.Util
- Habilita/Desabilita o campo [RichText] especificado.
FetchData(entityName, sqlFields, objSearchValue, orderBy)
Namespace: CRMGT.Page.Util
- Retorna um json com os registros da tabela especificada no parâmetro
-
Exemplo 1:
Faz um SELECT na tabela de [incident], retorna o campo [incidentStatusId]
onde o campo [originatingrecordid] seja igual a variável [incidentId]:
var incidentId = CRMGT.Page.Util.GetEntityRecordId(); var aSearch = []; var search = new Object(); search.field = "originatingrecordid"; search.type = "uniqueidentifier"; search.value = incidentId; aSearch.push(search); var data = CRMGT.Page.Util.FetchData('incident', 'incidentStatusId', aSearch);
-
Para o search.type você pode usar os seguintes valores:
bit char nchar varchar nvarchar datetime int decimal text uniqueidentifier -
Exemplo 2:
Usa o FetchData para efetuar uma busca do registro mais atual (instrução [DESC LIMIT 1] do MySQL) e [extrair] parte de um valor do campo [numocorrencia] da tabela [incident]
var data = CRMGT.Page.Util.FetchData( 'incident', 'SUBSTR(numocorrencia, 1, LOCATE("/", numocorrencia) - 1) + 1 num', null, 'num DESC LIMIT 1'); var nro = "1/" + (new Date()).getFullYear(); if (data && data.length > 0 && data[0].num != "") { nro = data[0].num + "/" + (new Date()).getFullYear(); }
QueryExecData(xml)
Namespace: CRMGT.Page.Util
- Retorna um json como resultado da execução da QueryExec passada como parâmetro.
- Lembre-se que, se você precisar efetuar uma busca de dados em apenas uma tabela, não existe a necessidade de uso do QueryExecData, utilize o FetchData, que faz montagem do SELECT diretamente no código JS.
-
Exemplo:
OnLoad configurado para executar a QueryExec:
Depurando a execução e analisando o resultado:
-
Na execução de uma QueryExec de UPDATE, na passagem de parâmetros, informe o atributo [type]. Ele não é obrigatório quando o param é do ipo UniqueIdentifier.
Exemplo:
Estes types seguem o padrão já estabelecido no SDK, sendo:
bit char nchar varchar nvarchar datetime int decimal text uniqueidentifier
GetEntityName()
Namespace: CRMGT.Page.Util
- Retorna o nome da tabela do formulário corrente
GetParentEntityName()
Namespace: CRMGT.Page.Util
- Retorna o nome da tabela [pai] do formulário corrente
GetEntityMetadataId()
Namespace: CRMGT.Page.Util
- Retorna o Guid da tabela do formulário corrente (no metadados do sistema)
GetEntityMetadataIdByName(entityName)
Namespace: CRMGT.Page.Util
- Retorna o Guid da tabela baseado no seu nome de Schema (no metadados do sistema)
GetEntityRecordId()
Namespace: CRMGT.Page.Util
- Retorna o Guid do Registro para a tabela corrente
GetParentEntityRecordId()
Namespace: CRMGT.Page.Util
- Retorna o Guid do Registro [pai] da tabela corrente
GetIndexRecordId()
Namespace: CRMGT.Page.Util
- Retorna o Guid do Registro para a tabela corrente, no formulário de LISTA de registros
GetIndexRecordListIds()
Namespace: CRMGT.Page.Util
- Retorna os Guids dos Registros [Selecionados] para a tabela corrente, no formulário de LISTA de registros
GetIndexEntityName()
Namespace: CRMGT.Page.Util
- Retorna o nome da tabela (schema name) a partir de uma LISTA de registros
GetCanSaveRecord()
Namespace: CRMGT.Page.Util
- True/false – Verifica se pode salvar um registro corrente no formulário
SetCanSaveRecord(value [true|false])
Namespace: CRMGT.Page.Util
- Determina se pode salvar um registro corrente no formulário
FormMode()
Namespace: CRMGT.Page.Util
- Retorna o Modo corrente do formulário:
- create
- add
- edit
- send
TriggerEnterActionOnField(id, value, frameId = "", eventName = "keydown")
Namespace: CRMGT.Page.Util
- Atribui um valor para um campo e logo em seguida executa um [Enter] nele.
- Por padrão, o comando vai usar o evento "keydown" do campo. Você pode especificar um evento diferente no parâmetro [eventName], como "keypress", por exemplo.
Dialogs
É possível utilizar diversos tipos de [dialogs] que fazem parte do Core do produto.
Não utilize estas funções com namespace, apenas faça referência direta ao nome das funções.
ShowDialog(action, _width, _height, _title, callFunc, closePreviousDialog, overflow, btns, fnCloseCallback)
- action - URL para visualização na Dialog
- _width, _height - valor númerico (em pixels)
- _title - Título da janela
- callFunc - Executa uma function quando a janela é Aberta. Passe o nome da function desejada neste parâmetro.
- closePreviousDialog - true|false - Fecha uma janela aberta (via ShowDialog) se existir
- overflow - Valores possíveis - visible, hidden, scroll e auto (valor padrão)
-
btns - Adiciona um conjunto de botões customizados.
Exemplo:
var btns = {}; btns["OK"] = function () { MyFunc(); }; btns["Cancelar"] = function () { CloseDialog(); };
-
fnCloseCallback - Executa uma function quando a tela é Fechada.
Passe o nome da function (ou anônima) desejada neste parâmetro.
Exemplo:
ShowDialog("/MyWebSite/Index", 850, 650, null, null, null, null, null, function () { // My JS code... });
ShowConfirmDialog(message, btnLabelYes, btnLabelNo, callbackFunc_Yes, callbackFunc_No)
- message - Texto da mensagem
- btnLabelYes - Label para o botão [yes]
- btnLabelNo - Label para o botão [no]
- callbackFunc_Yes - Executa uma function quando o usuário clica no botão [yes]. Passe o nome da function desejada (ou anônima) neste parâmetro.
- callbackFunc_No - Executa uma function quando o usuário clica no botão [no]. Passe o nome da function desejada (ou anônima) neste parâmetro.
-
Exemplo:
ShowConfirmDialog( "Confirma a exclusão?", "Sim", "Não", function () { DeleteRecordById(_id); }, function () { CloseDialog(); } );
ShowAlert(message, width, centerText, textFontSize, callbackFunc, imageType)
- message - Texto da mensagem
- width - largura da janela
- centerText - true|false
- textFontSize - Exemplo: font-size:12px; (O valor padrão é de 20px)
- callbackFunc - Executa uma function quando a janela é Fechada. Passe o nome da function desejada (ou anônima) neste parâmetro.
- imageType - warning (default), alert, error, success
-
Exemplo:
ShowAlert("Processo concluído...", 500, false, "font-size:15px;", function () { MyFunc(); }, "success");
/TreeViewCheckBoxForm/Index
-
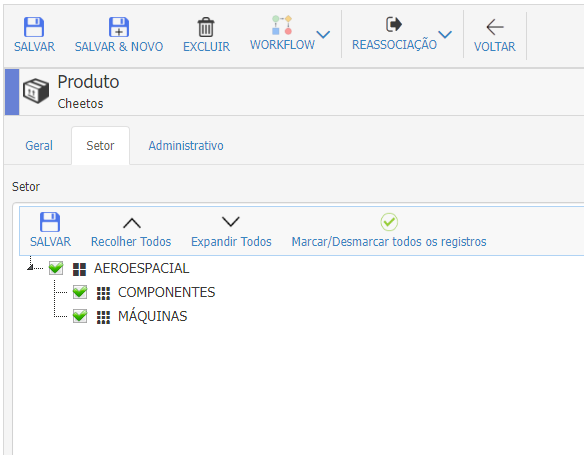
Utilize este componente se desejar efetuar um cadastro de informações na forma de uma [Árvore de Dados]
Por exemplo, dentro do cadastro de Produtos, você precisa informar os [Setores Industriais] para cada produto.
Os Setores possuem um cadastro na forma de árvore, onde cada setor possui seu registro [pai].
Então, para mostrar tudo isto de forma a continuar visualizando a árvore de setores e relacionar com o [Produto], faça o seguinte: - Crie um campo do tipo [iFrame] no cadastro de Produtos
- Informe a seguinte URL no campo [src] do iframe (no OnLoad do formulário)
- Onde:
- sqlTreeViewStatement - Informe o SELECT para preenchimento da árvore de dados
- parentIdFieldName - se refere ao campo de lookup de produto na tabela especificada no parâmetro [tableNameToStore]
- tableNameToStore - tabela de destino que conterá o [id] do [Produto] e do [Setor Industrial]
- tableNameToStoreFieldName - campo de lookup na tabela especificada no parâmetro [tableNameToStore]
var sqlTreeViewStatement = "SELECT UPPER(IndustrialSectorId) id,"; sqlTreeViewStatement += " UPPER(PrimaryIndustrialSectorId) parent,"; sqlTreeViewStatement += " name as text,"; sqlTreeViewStatement += " (CASE WHEN PrimaryIndustrialSectorId = '#' THEN 'root' ELSE 'child' END) type"; sqlTreeViewStatement += " FROM IndustrialSector"; sqlTreeViewStatement += " ORDER BY name, PrimaryIndustrialSectorId"; var iFrameSrc = "/TreeViewCheckBoxForm/Index"; iFrameSrc += "?sqlTreeViewStatement=" + btoa(sqlTreeViewStatement); iFrameSrc += "&parentIdFieldName=product_66dba258e5c4_id"; iFrameSrc += "&tableNameToStore=productIndustrialSector"; iFrameSrc += "&tableNameToStoreFieldName=industrialsector_47da919eba2f_id"; $("#industrialsector").attr("src", iFrameSrc);
Exemplo da configuração citada acima:
/TreeViewRegistration/Index
-
Utilize este componente se desejar efetuar um cadastro de informações na forma de uma [Árvore de Dados]
Por exemplo, se precisar cadastrar informações em uma tabela que posssui um relacionamento com ela mesma.
Imagine uma tabela de Setores Industriais. Cada registro pode ter um registro [pai], formando desta forma uma árvore de dados.
Então faça o seguinte: - Entre em Configurações -> Áreas
- Escolha ou crie uma área e adicione um [Item da Área]
- Como Url informe:
- /TreeViewRegistration/Index?tableName=[NomedoEsquemaDaTabela]
- Ex: /TreeViewRegistration/Index?tableName=industrialsector
Exemplo da configuração citada acima:

Note que ao clicar em algum nó da árvore, podemos visualizar mais campos para edição.
Estes campos são lidos do metadados da tabela criada no sistema.
Execução de Código JavaScript ao Entrar no Sistema
Você pode executar um código JavaScript depois de logar no sistema. Isto é útil se precisar manipular algum dado na tela logo ao entrar, como por exemplo, esconder um item do menu de acordo com o perfil do usuário logado.
O exemplo abaixo faz isto, se o usuário tiver o perfil de [Vendedor], não poderá ver um [item do menu] chamado [Área do Gestor].
Para habilitar este recurso faça o seguinte:
- Crie um [Web Resource do tipo Script] e dê o nome de [RunScriptWhenLoadingMenu]
- Adicione o código desejado:
var profile = CRMGT.UserConfig.Profile(); if (!CRMGT.Page.Util.IsNullOrEmpty(profile.userProfile)) { if (profile.userProfile[0].departmentFunctionName.toLowerCase() == "vendedor") { var _span = $("span").filter(function () { return (this.innerText == "Área do Gestor"); }); _span.closest("div").css("display", "none"); } }
Execução de Código JavaScript ao Entrar na Lista de Registros de Qualquer Tabela
Você pode executar um código JavaScript ao entrar na lista de registros de uma tabela. Isto é útil se precisar manipular algum objeto DOM nesta tela.
Para habilitar este recurso faça o seguinte:
- Crie um [Web Resource do tipo Script] e dê o nome de [RunScriptWhenLoadingGenFormIndex]
- Adicione o código desejado.
Utilização de Built-In Procedures nas Query Execs
Algumas Stored Procedures foram criadas para facilitar a manipulação de dados do CRM-GT.
GetEmailsFromMultiLookupFieldValue
Retorna os emails de todos os valores de um MultiLookup (de usuário ou contato).
Exemplo: busca dos participantes (campo multiLookup) da tabela de [AppointmentActivity] e execução da procedure para obter os emails destes participantes.
SET @users = ''; SET @emails = ''; SELECT participants FROM AppointmentActivity WHERE AppointmentActivityId = '9BF0C60B-1FDF-48E9-B2F0-33438515A6FD' INTO @users; CALL GetEmailsFromMultiLookupFieldValue(@users, @emails); SELECT @emails;
gabriel001@gmail.com,mauricio@hotmail.com,gtezini@hotmail.com,
MultiLookup_GetLabels
Adiciona um registro de [trigger] de workflow programaticamente.
Exemplo: busca dos participantes (campo multiLookup) da tabela de [AppointmentActivity] e execução da procedure para obter os [nomes] destes participantes.
SET @users = ''; SET @labels = ''; SELECT participants FROM AppointmentActivity WHERE AppointmentActivityId = '9BF0C60B-1FDF-48E9-B2F0-33438515A6FD' INTO @users; CALL MultiLookup_GetLabels(@users, @labels); SELECT @labels;
Gabriel Silva,Jose da Silva,gilberto
GetOriginatingRecordInfo
Retorna formatado o [name] do registro originador de uma determinada tabela.
Exemplo: Buscar o registro originador na qual uma [task] foi criada. Como resultado, veremos no exemplo abaixo, que a task foi criada a partir de uma [conta].
SET @originatingRecordInfo = ''; CALL GetOriginatingRecordInfo('task', '0cad354b-311a-42d0-a9a0-6b0e85dbdff0', @originatingRecordInfo); SELECT @originatingRecordInfo;
Gabriel Silva (account)
SplitString
Efetua um Split em uma string e adiciona o resultado em uma TempTable.
Exemplo:
SET @value = 'slice1, slice2, slice3, slice4, slice5'; DROP TEMPORARY TABLE IF EXISTS temp; CREATE TEMPORARY TABLE temp (rownumber INT, val VARCHAR(255)); CALL SplitString(@value, ",", "temp"); SELECT * FROM temp;
1 slice1 2 slice2 3 slice3 4 slice4 5 slice5
InsertIntoWorkflowTrigger
Adiciona um registro de [trigger] de workflow programaticamente.
Exemplo: Criar um gatilho para executar todos os workflows de [update] para a tabela de [incident], quando o campo [statuscode] mudar.
InsertIntoWorkflowTrigger('incident', 'update', @incidentId, 'statuscode', null, null, null, null, null);
Este método recebe os seguintes principais params:
1º - nome da Tabela (schema name)
2º - nome do Evento (create/update/delete/assign)
3º - RecordID (por ex, o id de um incident que foi atualizado diretamente no banco)
4º - Se precisar configurar o workflow para que seja executado somente quando campos específicos forem alterados, passe-os aqui, separados por vírgula
Existem mais params, são opcionais (passe null por padrão), sendo:
- DeleteCurrentWorkflowTrigger (true/false) - default null
- CurrentWorkflowTriggerId (guid) - default null
- LastStepNotExecuted (usado internamente pelo sistema) - default null
- SpecificWorkflowDesignId (usado internamente pelo sistema) - default null
- WorkflowTriggerUserId (ID de um usuário do sistema, representando um usuário que iniciou o trigger de wk) - default null
-Importante:
- Se vc precisar Reprocessar [somente] um workflow específico, passe o Id para o parâmetro SpecificWorkflowDesignId e passe NULL para o 2º parâmetro (nome do evento)
-Por que isto é importante? Lembre-se que se o 2º parâmetro estiver preenchido, então o motor de workflow vai rodar [todos] os workflows do [evento] especificado (para o registro corrente).
- Se vc precisar Reprocessar [somente] um workflow específico, sendo que este workflow é do tipo [update] com configuração para ser executado [somente quando campos específicos mudarem] , passe o Id para o parâmetro SpecificWorkflowDesignId e passe "update" para o 2º parâmetro (nome do evento)
Assinar:
Postagens (Atom)